
Arbeiten mit exportierten Aufzeichnungen im AWS S3-Bucket
Nachdem die AWS S3 Integration von Massenaufzeichnungen eingerichtet ist, können Sie Aufzeichnungen, die sich in Genesys Cloud befinden, in Massen in Ihren AWS S3 Bucket exportieren. Dieser Export kann automatisch über eine QM-Richtlinie oder explizit durch Aufruf der API für Massenaufzeichnungsaktionen erfolgen.
Dieser Artikel beschreibt den Inhalt, der in Ihr AWS S3-Bucket exportiert wird.
Inhalt des AWS S3-Buckets
Aufzeichnungsdateien werden in den AWS S3-Bucket in Ordnern mit der folgenden Struktur exportiert:
s3://{bucket}/{organizationId}/year={year}/{month={month}/day={day}/hour={hourOfDay}/conversation_id={conversationId}/
| Platzhalter | Beschreibung |
|---|---|
| (Eimer) | Der Name des S3-Buckets. |
| {OrganisationId} | Die Organisations-ID. |
| {Jahr} | Das Jahr, in dem das Gespräch begann. |
| {Monat} | Der Monat, in dem das Gespräch begann (in Ziffern). |
| {day} | Der Tag, an dem das Gespräch begann. |
| {hourOfDay} |
Die Stunde, in der das Gespräch begann. |
| {conversationId} |
Die Konversations-ID. |
Der Ordner enthält alle Aufzeichnungsdateien, die während des Gesprächs gespeichert werden. Jede Aufzeichnungsdatei enthält eine Aufzeichnung, und der Name der Datei ist die Aufzeichnungs-ID.
Jede Aufzeichnungsdatei hat eine entsprechende JSON-Metadatendatei. Der Name der JSON-Metadaten-Datei wird mit dem Suffix "_metadata.json" versehen.
Die Metadaten können für die Suche nach der exportierten Aufnahme verwendet werden. Weitere Informationen finden Sie im Athena+Glue Beispiel (ein Beispiel für einen Aufzeichnungssuchdienst).
Die Metadaten-Datei ist im JSON-Format mit dem folgenden Schema.
{
“$schema”: “http://json-schema.org/draft-04/schema#”,
„Typ“: „Objekt“,
"Eigenschaften": {
„Medientyp“: {
"Beschreibung": „Medientyp (einer von Anruf, Chat, E-Mail, Nachricht, Bildschirm)“,
„Typ“: „Zeichenfolge“
},
„Mediensubtyp“: {
"Beschreibung": „Der Untertyp der Aufzeichnung (einer von Trunk, Station, Consult, Screen)“,
„Typ“: „Zeichenfolge“
},
„Medienbetreff“: {
"Beschreibung": „Das Thema der Aufnahme“,
„Typ“: „Zeichenfolge“
},
„Anbieter“: {
"Beschreibung": „Art des Anbieters für die Aufzeichnung, zum Beispiel Edge“,
„Typ“: „Zeichenfolge“
},
„Benutzer-IDs“: {
"Beschreibung": „Liste der Benutzer“,
„Typ“: „Array“,
"Artikel": [
{
„Typ“: „Zeichenfolge“
}
]
},
„Startzeit“: {
"Beschreibung": „Startzeit der Aufnahmen“,
„Typ“: „Zeichenfolge“
},
„Endzeit“: {
"Beschreibung": „Endzeit der Aufnahmen“,
„Typ“: „Zeichenfolge“
},
„DauerMs“: {
"Beschreibung": „Dauer der Aufnahme“,
„Typ“: „Ganzzahl“
},
“initialDirection”: {
"Beschreibung": „Anfängliche Gesprächsrichtung (eingehend/ausgehend)“,
„Typ“: „Zeichenfolge“
},
„aniNormalisiert“: {
"Beschreibung": „ANI“,
„Typ“: „Zeichenfolge“
},
„aniDisplayable“: {
"Beschreibung": „ANI in anzeigbarer Form“,
„Typ“: „Zeichenfolge“
},
“dnisNormalized”: {
"Beschreibung": „DNIS“,
„Typ“: „Zeichenfolge“
},
„dnisDisplayable“: {
"Beschreibung": „DNIS in anzeigbarer Form“,
„Typ“: „Zeichenfolge“
},
„Warteschlangen-IDs“: {
"Beschreibung": „Liste der Warteschlangen-IDs für die Aufzeichnung“,
„Typ“: „Array“,
"Artikel": [
{
„Typ“: „Zeichenfolge“
}
]
},
„WrapupCodes“: {
"Beschreibung": „Abschlusscodes für das Gespräch“,
„Typ“: „Array“,
"Artikel": [
{
„Typ“: „Zeichenfolge“
}
]
},
„Organisations-ID“: {
"Beschreibung": „Eindeutige ID für die Konversation“,
„Typ“: „Zeichenfolge“
},
„Konversations-ID“: {
"Beschreibung": „Eindeutige ID, die mit der Konversation verknüpft ist“,
„Typ“: „Zeichenfolge“
},
„GesprächsStartzeit“: {
"Beschreibung": „Startzeit des Gesprächs“,
„Typ“: „Zeichenfolge“
},
„conversationEndTime“: {
"Beschreibung": „Endzeitpunkt des Gesprächs“,
„Typ“: „Zeichenfolge“
},
„Aufnahme-ID“: {
"Beschreibung": „Eindeutige ID für die Aufnahme“,
„Typ“: „Zeichenfolge“
},
„Dateipfad“: {
"Beschreibung": „Ursprünglicher Pfad der Aufnahme“,
„Typ“: „Zeichenfolge“
},
„Dateigröße“: {
"Beschreibung": „Größe der Aufnahmedatei“,
„Typ“: „Ganzzahl“
},
„Nachrichtentyp“: {
"Beschreibung": „Art der Nachrichtenplattform, von der die Nachricht stammt, z. B. SMS, Twitter, Line, Facebook, WhatsApp, Webmessaging, Open, Instagram“,
„Typ“: „Zeichenfolge“
},
„Sprach-IDs“: {
"Beschreibung": „Kennung für die Sprache“,
„Typ“: „Array“,
"Artikel": [
{
„Typ“: „Zeichenfolge“
}
]
},
„Bildschirminformationen“: {
"Beschreibung": „Bildschirmspezifische Informationen, einschließlich Bildschirm-ID, X- und Y-Position, Auflösungsinformationen“,
„Typ“: „Objekt“
}
},
"erforderlich": [
„Medientyp“,
„Anbieter“,
„Startzeit“,
„Endzeit“,
„DauerMs“,
„Organisations-ID“,
„Konversations-ID“,
„GesprächsStartzeit“,
“conversationEndTime”,
„Aufnahme-ID“,
„Dateipfad“,
„Dateigröße“
]
}
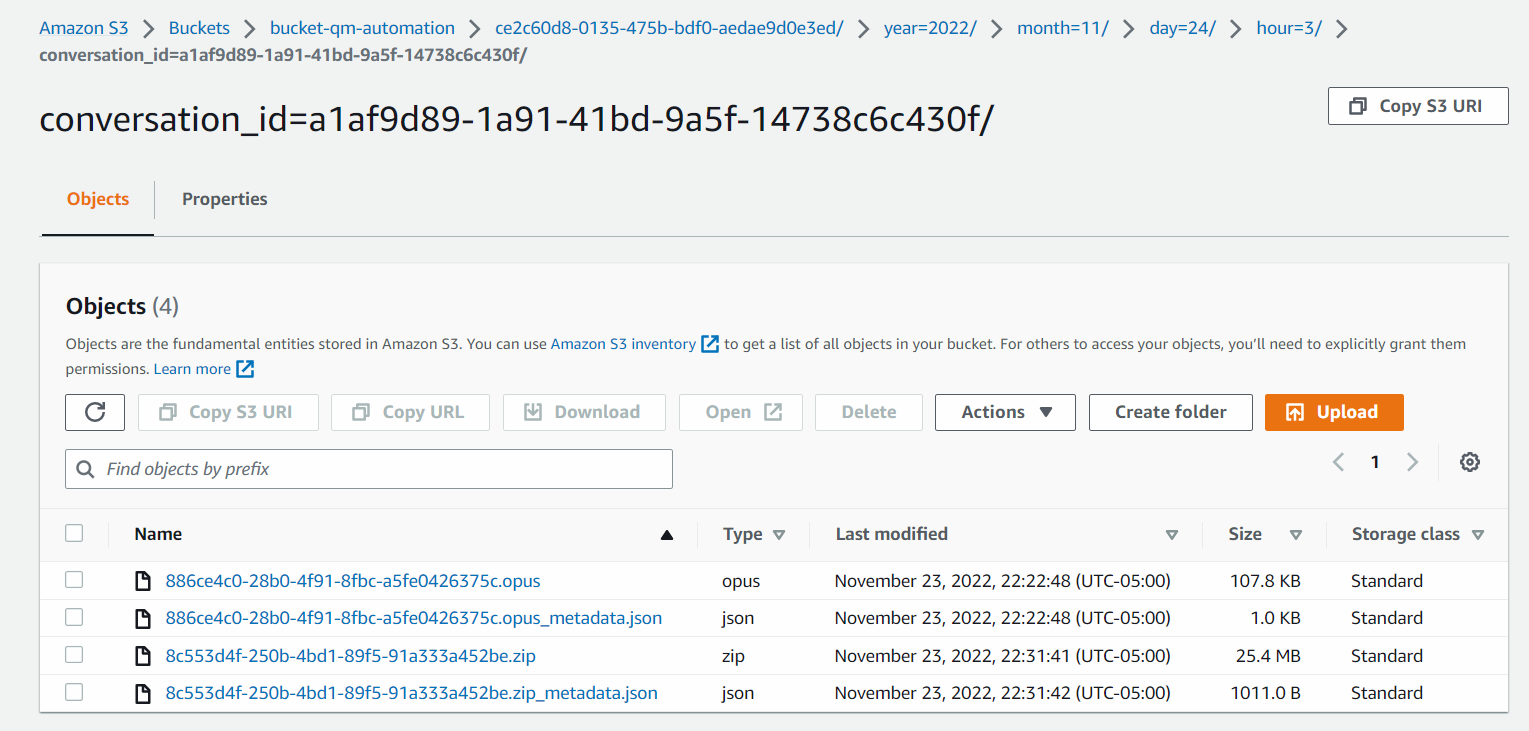
Ein Gespräch mit aktivierter Bildschirmaufzeichnung kann beispielsweise den folgenden Ordnerinhalt haben.
In der Abbildung unten ist die .opus-Datei die Audioaufnahmedatei, die .zip-Datei enthält die Bildschirmaufnahmedatei, und die .json-Dateien sind die JSON-Metadaten, die mit den jeweiligen Mediendateien verbunden sind.
Klicken Sie auf das Bild, um es zu vergrößern.
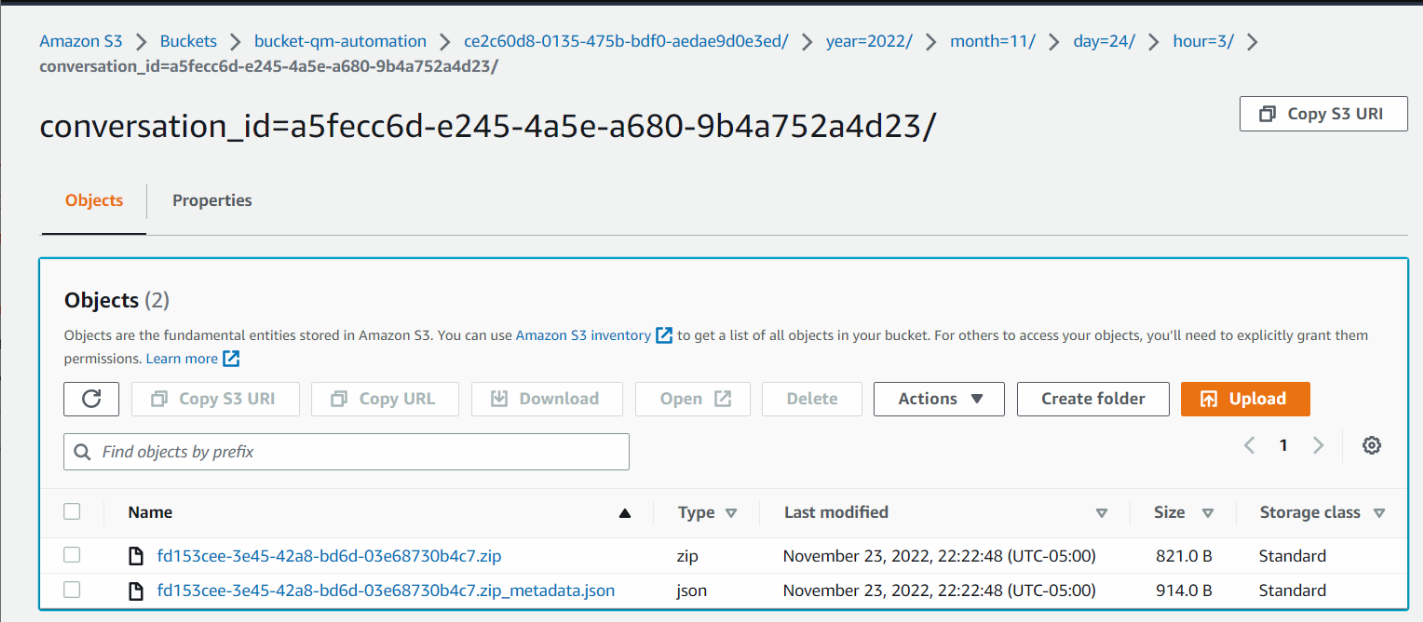
Eine digitale Konversation kann den folgenden Ordnerinhalt haben.
In der Abbildung unten enthält die .zip-Datei die digitale Aufzeichnungsdatei, und die .json-Datei ist die entsprechende JSON-Datei.
Klicken Sie auf das Bild, um es zu vergrößern.
Verschlüsselung
Ihr S3-Bucket ist bereits mit AWS S3 Server-Side Encryption (SSE) konfiguriert. Es kann mit Verschlüsselungsschlüsseln aktiviert worden sein, die von Amazon S3 verwaltet werden (SSE-S3), oder mit den von AWS verwalteten Schlüsseln oder vom Kunden bereitgestellten Schlüsseln vom AWS Key Management Service (SSE-KMS) aktiviert worden sein.
AWS S3 Server-Side Encryption (SSE) sichert die Aufzeichnungsdateien im S3-Bucket im Ruhezustand. Wenn die Dateien aus dem Bucket abgerufen werden, entschlüsselt AWS den Dateiinhalt automatisch.
Wenn Ihr System eine zusätzlich aktivierte Recording Export Encryption enthält, müssen Sie den Dateiinhalt selbst entschlüsseln, nachdem Sie die Dateien aus dem S3-Bucket abgerufen haben.